What Is Cluster Sampling? | Examples & Definition
Cluster sampling is a probability sampling method where researchers divide a population into smaller groups called clusters. They then form a sample by randomly selecting clusters.
Cluster sampling is commonly used to study large populations, especially those with a wide geographic distribution. Researchers use existing groups or units (such as schools or towns) as their clusters.
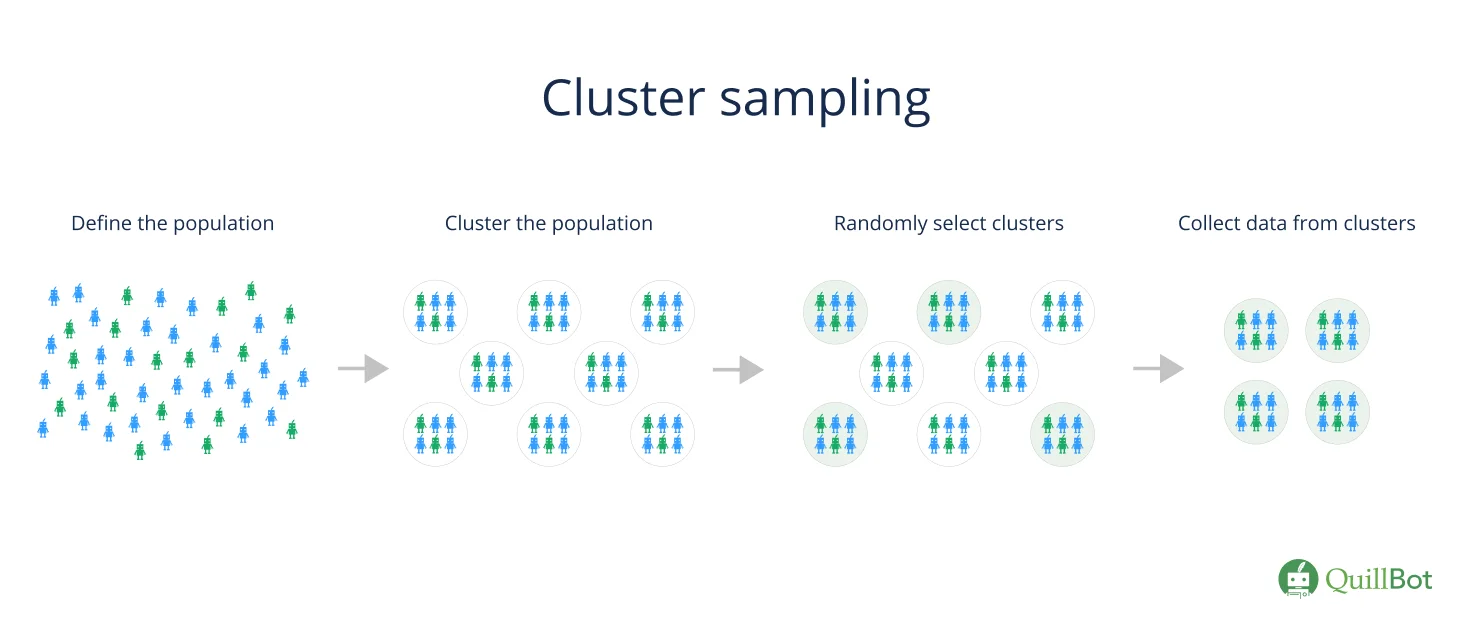
What is cluster sampling?
The most basic form of cluster sampling is single-stage cluster sampling. It consists of four steps.
It would be difficult and time-consuming to create a list of all eighth-graders and draw a sample. Instead, you can easily make a list of all schools, draw a random sample, and then collect data from the eighth-graders of the randomly selected schools. That’s why you opt for a clustered sample.
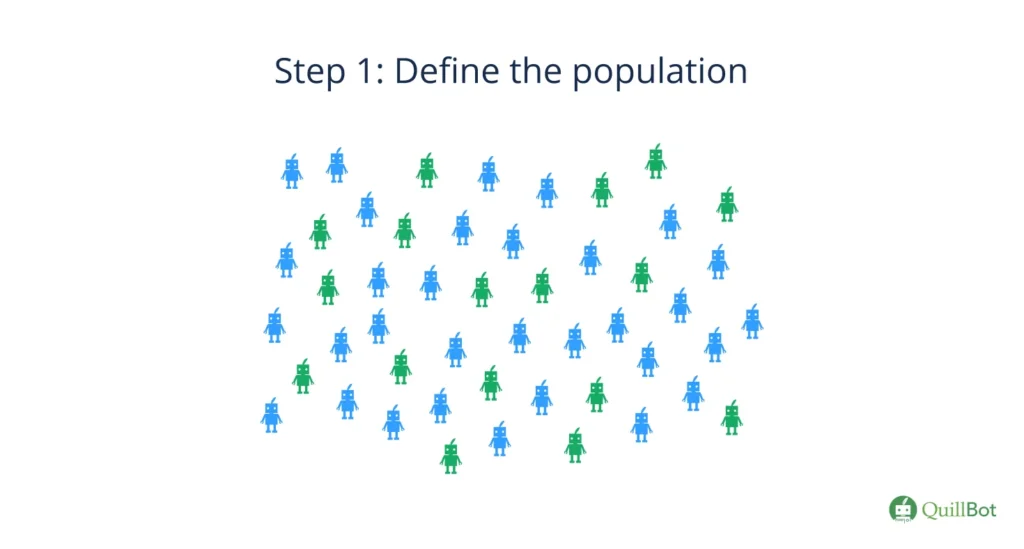
Step 1: Determine the population
The first step for every sampling method is defining the population you are interested in.
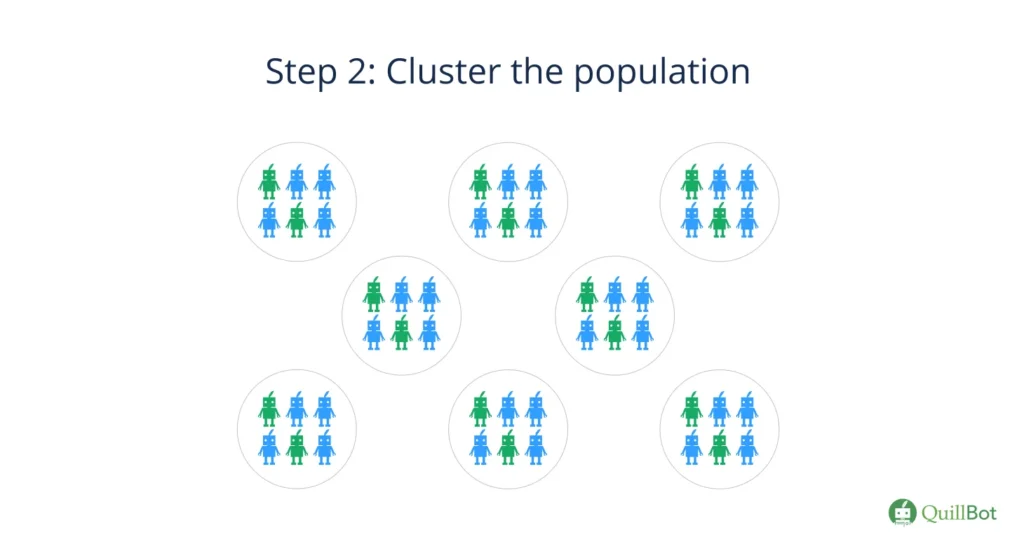
Step 2: Divide the sample into clusters.
The general quality of the clusters and the extent to which they are representative of the larger population influence the validity of your results. Your clusters should meet the following criteria:
- Each cluster should be as diverse as possible. Every potential attribute of the population (e.g., socio-economic status, gender, age) should appear in each cluster.
- The distribution of traits should be approximately equal for each cluster, and this distribution in turn should match that of the entire population.
- The clusters should collectively constitute the entire population.
- There should be no overlap between clusters, so participants (or other research units) shouldn’t be part of more than one cluster.
In the ideal situation, each cluster is a perfect reflection of the population. In practice, it is often not possible to ensure that the characteristics of the population are perfectly distributed among the clusters. Therefore, you can’t make as strong statistical claims with this method as with other random sampling methods, and there is a risk of selection bias or other research biases.
Since clusters often form naturally (towns, schools, sports clubs), they tend to be more homogeneous in nature than the population itself. For example, you may survey a Christian school when not all of your population is Christian. Then that one cluster does not constitute a representative, heterogeneous sample. You have to take this into account in your research because this sampling method could harm the (external) validity of your research.
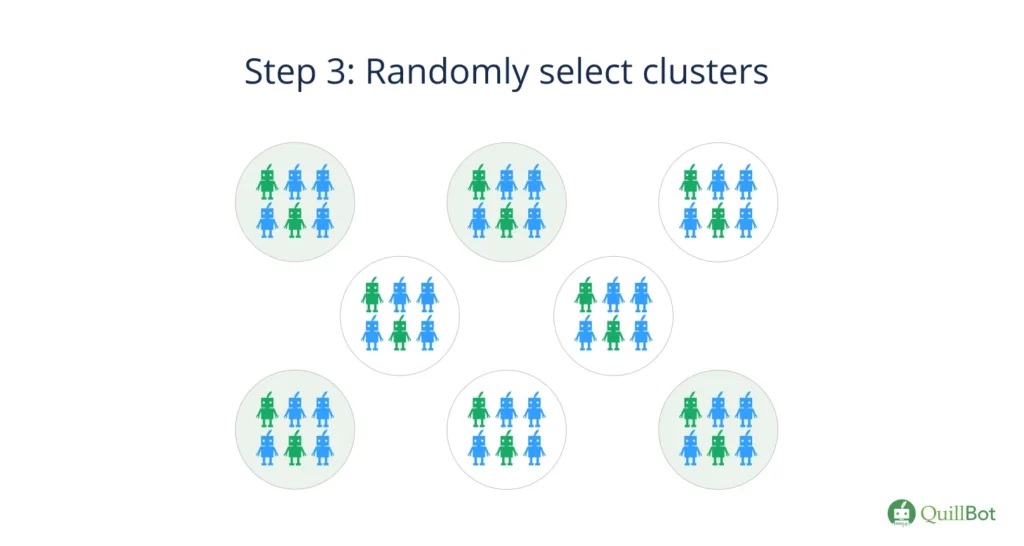
Step 3: Conduct random sampling to select clusters
Each cluster represents the population, so random sampling of those clusters ensures that you are in effect replicating a single random sample. This increases the validity of your results.
If the clusters do not represent the population, a random sample still ensures that you collect data from several clusters, which would still give you an overview of the entire population.
You determine the number of clusters based on the required sample size, which is based on the size of the population, your chosen confidence level and confidence interval, and your estimate of the standard deviation.
By entering these data into a free sample calculator, you can calculate the required sample size.
Step 4: Collect data from your sample
Next, you conduct your research and collect data from the selected clusters.
Stratified vs cluster sampling
Stratified sampling and cluster sampling show some overlap, but there are also distinct differences.
- Stratified sampling is a sampling method where the population gets divided into groups with a specific trait (strata). Then you randomly select members from each stratum to collect data from. Each stratum contains units (e.g., people) that are similar in terms of your variable of interest (e.g., they all have the same age). Each stratum on its own is not a mini-version of the population.
You divide the population into groups based on their age. You then draw a random sample from each age group to collect data from.
- Cluster sampling is a sampling method where the population is naturally divided into clusters (e.g., because of a geographic characteristic). Data is then collected from the entire cluster without the need for participants to meet certain criteria. Each cluster is a mini version of the entire population.
You divide the town into multiple neighborhoods and draw a random sample from each neighborhood to collect data using a survey.
What is multistage cluster sampling?
In multistage cluster sampling, you don’t collect data from all the individuals in your selected clusters. Instead, you conduct another random sample after you have selected the clusters, so that only a few individuals from each cluster end up in your sample.
Next, you collect data from these individuals. This is called double-stage sampling.
You can repeat this procedure several times (i.e., draw another random sample). This is called multistage sampling.
This method is a good choice when single-stage cluster sampling is too costly, time-consuming, or not feasible.

- You draw a random sample of eight-grade classes from each school.
- You draw another random sample to select a number of students out of these selected classes.
This leaves you with a much smaller final sample, which makes data collection easier.
Cluster sampling advantages
Cluster sampling has many advantages:
- Cluster sampling is inexpensive and efficient, especially if your population covers a large geographic area and it would be difficult to draw a different type of sample.
- Cluster sampling is among the random sampling methods, so you can ensure high external validity if the population is clustered appropriately.
Cluster sampling disadvantages
Cluster sampling also comes with some disadvantages:
- The internal validity is lower than for a single random sample, especially if you used multi-stage cluster sampling.
- If your clusters don’t accurately represent the entire population, it is harder to obtain (externally) valid, unbiased results based on your sample.
- Clustered sampling requires thorough preparation, and it is often more complex than other sampling methods.
Frequently asked questions about cluster sampling
- What are the different types of cluster sampling?
-
In all three types of cluster sampling, you start by dividing the population into clusters before drawing a random sample of clusters for your research. The next steps depend on the type of cluster sampling:
- Single-stage cluster sampling: you collect data from every unit in the clusters in your sample.
- Double-stage cluster sampling: you draw a random sample of units from within the clusters and then you collect data from that sample.
- Multi-stage cluster sampling: you repeat the process of drawing random samples from within the clusters until you’ve reached a small enough sample to collect data from.
- What are the advantages of cluster sampling?
-
Cluster sampling is generally more inexpensive and efficient than other sampling methods. It is also one of the probability sampling methods (or random sampling methods), which contributes to high external validity.
- What are the disadvantages of cluster sampling?
-
Cluster sampling usually harms internal validity, especially if you use multiple clustering stages. The results are also more likely to be biased and invalid, especially if the clusters don’t accurately represent the population. Lastly, cluster sampling is often much more complex than other sampling methods.
Cite this QuillBot article
We encourage the use of reliable sources in all types of writing. You can copy and paste the citation or click the "Cite this article" button to automatically add it to our free Citation Generator.
Merkus, J. (2025, November 26). What Is Cluster Sampling? | Examples & Definition. Quillbot. Retrieved May 20, 2026, from https://quillbot.com/blog/research/cluster-sampling/
