Experimental Design | Types, Definition & Examples
An experimental design is a systematic plan for conducting an experiment that aims to test a hypothesis or answer a research question.
It involves manipulating one or more independent variables (IVs) and measuring their effect on one or more dependent variables (DVs) while controlling for other variables that could influence the outcome.
The goal of an experimental design is to isolate the effect of the independent variable on the dependent variable while controlling for other variables that could influence the outcome. By doing so, researchers can:
- Test causal relationships between variables
- Identify the effects of specific interventions or treatments
- Make predictions about future outcomes
Your sample needs to be representative to draw valid conclusions from your data. If it’s unethical, hard, or even impossible to randomly assign participants to a control or treatment group, it’s best to use an observational design instead.

Table of contents
- What is an experimental design?
- Step 1: Define your research question and variables
- Step 2: Formulate a specific, testable hypothesis
- Step 3: Develop experimental treatments
- Step 4: Divide subjects between treatment and control groups
- Step 5: Decide how to measure your dependent variable
- Types of experimental design
- Frequently asked questions about experimental design
What is an experimental design?
Experimental designs are used to investigate causal relationships by manipulating one or more independent variables and observing their impact on one or more dependent variables.
An experimental design involves a structured approach to testing a hypothesis. A thorough understanding of the study subject is essential for a well-designed experiment.
There are five crucial steps in designing an experiment:
- Define your research question and variables
- Formulate a specific, testable hypothesis
- Develop experimental treatments
- Divide subjects between treatment and control groups
- Decide how to measure your dependent variable
Step 1: Define your research question and variables
The first step is to formulate the research question for your experimental design.
Experimental design example: Research question
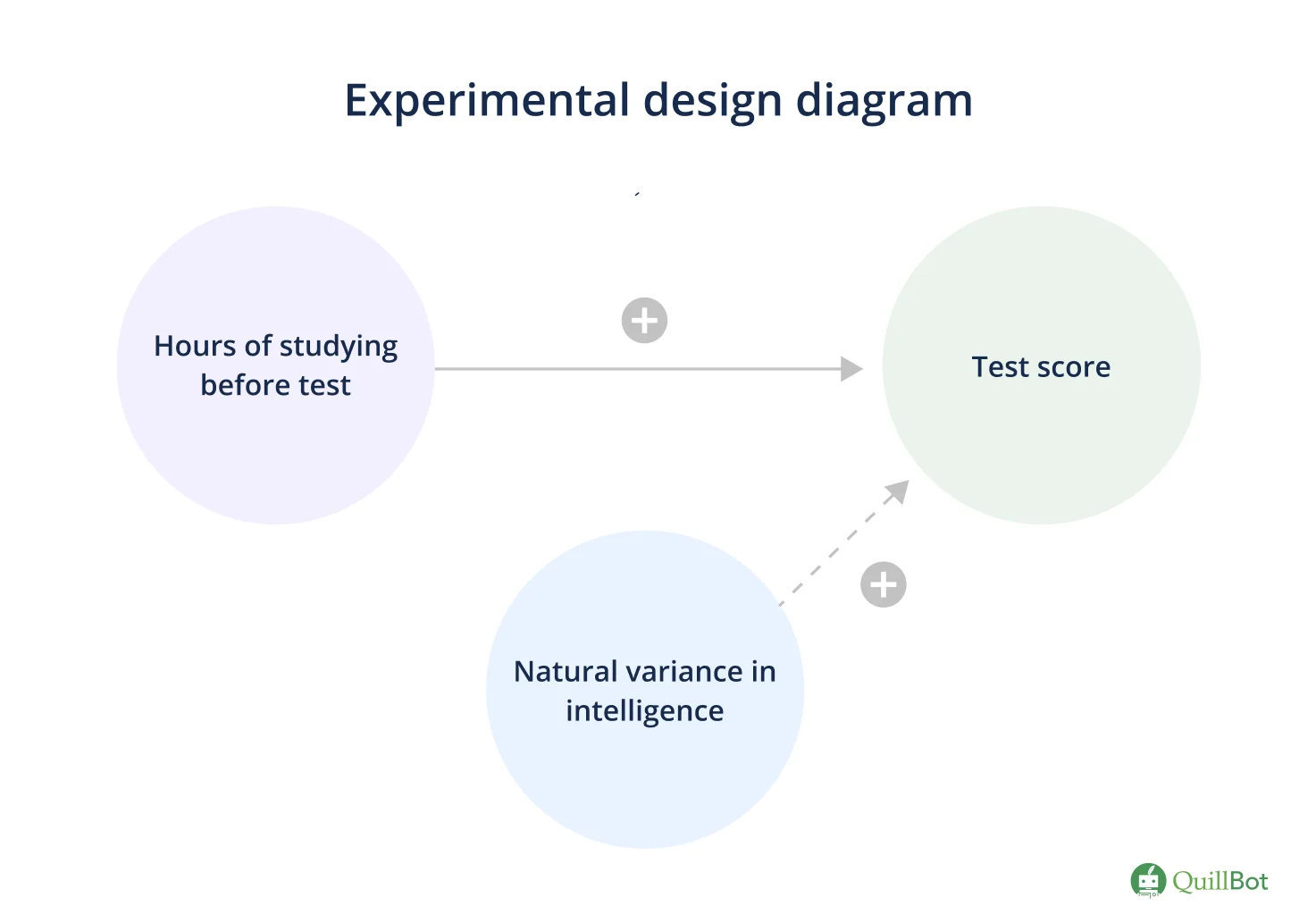
You’re interested in how studying influences test scores. Specifically, you want to know how the number of hours a person studies before a test affects their test score.
In order to formulate a hypothesis, you first need to understand what the independent and dependent variables of your study are.
- The independent variable is the variable you’re going to manipulate. In this case, it’s the number of hours someone studies before a test.
- The dependent variable is the variable you’re going to measure. In this case, it’s the test score.
To create your experimental design, you also need to take into account extraneous variables, such as confounding variables, because you need to control for these in your design.
- An extraneous variable is a variable you’re not interested in studying that can still affect your outcome. You need to control for them to make sure the observed effect is caused by the manipulation of your independent variable. In this case, an extraneous variable could be natural variation in intelligence among individuals.
To visualize your design, you can combine the variables into an experimental design diagram. You use solid and dotted line arrows to indicate possible relationships, as well as plus and minus signs to show the predicted effect.
Step 2: Formulate a specific, testable hypothesis
Your conceptual understanding of the phenomenon you’re studying allows you to formulate a testable hypothesis for your research question.
In most cases, you write a null hypothesis (H0) that predicts no relationship between the independent and dependent variables and an alternate hypothesis (H1 or Ha) that predicts a relationship between the variables.
The number of hours someone studies before a test does not correlate with their test score.
Alternate hypothesis
Increasing the number of hours someone studies before a test leads to an increase in their test score.
The next steps describe how to design a controlled experiment, where you must be able to measure the dependent variable(s) precisely, control for any extraneous variables, and systematically and accurately manipulate the independent variable(s).
If your topic or set-up doesn’t allow for this, you should use a different type of research design instead.
Step 3: Develop experimental treatments
The way you manipulate the independent variable(s) of your research affects the external validity (and thus, the generalizability) of the results.
You need to decide how widely and finely you want to vary your independent variable(s).
- You can choose to vary the number of study hours just slightly below or above the average studying time before a test.
- You can choose to vary the number of hours over a wider range to mimic more extreme scenarios.
How finely will you vary your independent variable?
You can treat studying as:
- a categorical variable, where you either allow a binary option (either you study or you don’t) or a variable with levels (no studying, a little, a lot).
- a continuous variable, where every value can occur (number of hours studied).
You can’t always choose how widely or finely you want to vary your independent variable. In some cases, it’s decided for you because of the topic or variables.
Step 4: Divide subjects between treatment and control groups
It’s important to take into account the sample size of your study. Usually, the experiment’s statistical power increases as the sample size increases, which means you can be more confident about your results. It’s best to use a sample size calculator to calculate the appropriate sample size.
Then, you need to establish which groups you’ll have for your study. An experiment should always contain at least one experimental group and one control group, but it’s possible to have more experimental groups if you have more levels of treatment (e.g., no studying at all, studying a little, studying a lot).
The control group shows us what the results for the experimental group would have been if we hadn’t manipulated the independent variable.
When you assign your participants to groups, you need to make two decisions:
- Completely randomized design vs. randomized block design
- Between-subjects design vs. within-subjects design
Completely randomized design vs randomized block design
An experiment is often completely randomized, but in some cases, you need to randomize within blocks (or strata).
- A completely randomized design allows every participant to be randomly assigned to a treatment group.
- For example, you use a random number generator to assign all participants to a treatment group
- A randomized block design (or stratified random design) requires you to group the participants based on a shared trait (e.g., age) before randomly assigning them to a treatment group within these groups.
- For example, you first group participants based on gender, and then you randomly assign study treatments within these groups.
When it’s not ethical or practical to use randomization, researchers might opt for a partially-random or non-random design. This is called a quasi-experimental design instead of an experimental design.
Between-subjects design vs within-subjects design
If you opt for a between-subjects design, participants only receive one of the possible levels of an experimental manipulation. This design is also called an independent measures design or a classic ANOVA design.
Subjects can be randomly assigned to one condition, or you can use matched pairs to ensure that each treatment group has the same variety of participants in the same proportions. This often happens in social or medical research.
If you opt for a within-subjects design, all participants experience every condition of the experimental manipulation consecutively, and you measure the outcome of each manipulation. This is also known as a repeated measures design.
For within-subjects designs, you often have to use counterbalancing, which is the act of randomizing the order of manipulations among participants. This way, you make sure the order of manipulations does not affect the findings.
Participants are randomly assigned to a level of studying (none, low, high).
Within-subjects design
Participants consecutively take part in all levels of studying (none, low, high), and the order in which they participate in these groups is randomized.
Step 5: Decide how to measure your dependent variable
For the last step, you have to choose one or multiple data collection methods to measure the outcomes for your dependent variable(s). You need to decide on reliable, valid measurements to reduce the risk of error or bias.
Some variables can be measured with scientific equipment, which typically makes for very reliable outcomes. An example of this is measuring time with a stopwatch. Other variables need to be operationalized before you can measure them.
Suppose, instead, we were investigating how the amount of time spent studying affects test anxiety. There is no standard measurement of test anxiety, so we would need to operationalize it. This could be done by, for example, administering a questionnaire to participants that asks them to self-report on their anxiety. We could also use physiological measures related to anxiety, such as heart rate, blood pressure, and respiratory rate.
Your choice of measurement affects the level of your data (nominal, ordinal, interval, or ratio) and, therefore, the types of statistical analysis you can conduct to analyze your data.
Types of experimental design
There are three main types of experimental designs:
Between-subjects design
In a between-subjects design, each participant is exposed to only one level of the independent variable. This design is often used in surveys, interviews, and observational studies.
Within-subjects design
In a within-subjects design, each participant is exposed to multiple levels of the independent variable. This design is often used in laboratory studies, where participants are tested multiple times under different conditions.
Mixed-subjects design
In a mixed-subjects design, a combination of between-subjects and within-subjects designs, where participants are tested under different conditions at multiple points in time and then compared to each other.
The between-subjects factor is the storytelling method. Participants either participate in storytelling method A or B but not in both. The within-subjects factor is the timepoint at which their reading skills are measured. All participants’ reading skills are measured at three different timepoints.
Some people also make a distinction between factorial design, randomized controlled trials, and a cross-over design.
Factorial design
In a factorial design, two or more independent variables are manipulated simultaneously. This design is often used in laboratory studies, where researchers want to investigate the interaction between multiple variables.
Randomized controlled trial (RCT)
In a randomized controlled trial (RCT), a type of between-subjects design that involves randomly assigning participants to treatment or control groups. This design is often used in medical and social science research to test the effectiveness of interventions.
Crossover design
In a crossover design, participants are randomly assigned to receive different levels of the independent variable at different times. This design is often used in clinical trials to test the effectiveness of multiple treatments.
Your choice of design depends on the research question and variables. Often, multiple designs are possible.
Frequently asked questions about experimental design
- What are the 4 principles of experimental design?
-
The four principles of experimental design are:
- Randomization: This principle involves randomly assigning participants to experimental conditions, ensuring that each participant has an equal chance of being assigned to any condition. Randomization helps to eliminate bias and ensures that the sample is representative of the population.
- Manipulation: This principle involves deliberately manipulating the independent variable to create different conditions or levels. Manipulation allows researchers to test the effect of the independent variable on the dependent variable.
- Control: This principle involves controlling for extraneous or confounding variables that could influence the outcome of the experiment. Control is achieved by holding constant all variables except for the independent variable(s) of interest.
- Replication: This principle involves having built-in replications in your experimental design so that outcomes can be compared. A sufficient number of participants should take part in the experiment to make sure that randomization allows for groups with a similar distribution. This increases the chance of detecting true differences.
- What are the two groups in an experimental design?
-
In experimental design, the two main groups are:
- Treatment group: This group is exposed to the manipulated independent variable, and the researcher measures the effect of the treatment on the dependent variable.
- Control group: This group is not exposed to the manipulated independent variable (the variable being changed or tested). The control group serves as a reference point to compare the results of the experimental group to.
In other words, the control group is used as a baseline to compare with the treatment group, which receives the experimental treatment or intervention.
Two groups in experimental design example You want to test a new medication to treat headaches. You randomly assign your participants to one of two groups:- The treatment group, who receives the new medication
- The control group, who receives a placebo
- What are advantages of using a within-participant design in experimental research?
-
A within-participant design, also known as a repeated-measures design, is a type of experimental design where the same participants are assigned to multiple groups or conditions. Some advantages of this design are:
- Increased statistical power: By using the same participants across multiple conditions, you can reduce the number of participants needed to detect a significant effect, which can lead to increased statistical power.
- Reduced between-participants variability: Since each participant is tested multiple times, the variability between participants is reduced, which can result in more accurate and reliable estimates of the effect.
- Better control over extraneous variables: By using the same participants across multiple conditions, you can better control for extraneous variables that might affect the outcome, as these variables are likely to be constant across conditions.
- Increased precision: Within-participant designs can provide more precise estimates of the effect size, as the same participants are used across all conditions.
- Reduced sample size: Depending on the research question and design, a within-participant design can require fewer participants than a between-participants design, which can reduce costs and increase efficiency.
It’s important to note that within-participant designs also have some limitations, such as increased risk of order effects (where the order of conditions affects the outcome) and carryover effects (where the effects of one condition persist into another condition).
- What is a pre-experimental design?
-
A pre-experimental design is a simple research process that happens before the actual experimental design takes place. The goal is to obtain preliminary results to gauge whether the financial and time investment of a true experiment will be worth it.
Pre-experimental design example A researcher wants to investigate the effect of a new type of meditation on stress levels in college students. They decide to conduct a small pre-experiment with 10 college students who are already interested in meditation.The students are asked to participate in a 30-minute meditation session once a week for 4 weeks. The students’ stress levels are measured before and after the meditation sessions with a standardized questionnaire.
The researcher compares the outcomes and notices significant differences in stress scores. They decide to move forward with a more costly and time-consuming experiment where they take into account all criteria for an experimental design (e.g., random assignment of participants, control group, controlling for extraneous variables).
- Why is randomization important in an experimental design?
-
Randomization is a crucial component of experimental design, and it’s important for several reasons:
- Prevents bias: Randomization ensures that each participant has an equal chance of being assigned to any condition, minimizing the potential for bias in the assignment process.
- Controls for confounding variables: Randomization helps to distribute confounding variables evenly across conditions, reducing the risk of spurious correlations between the independent variable and the outcome.
- Increases internal validity: By randomly assigning participants to conditions, you can increase the confidence that any observed differences between conditions are due to the independent variable and not some other factor.
- What is an experimental design diagram?
-
An experimental design diagram is a visual representation of the research design, showing the relationships among the variables, conditions, and participants. It helps researchers to:
- Clarify the research question and hypotheses
- Identify the independent, dependent, and control variables
- Determine the experimental conditions and treatment levels
- Plan the sampling and data collection procedures
- Visualize the flow of participants through the study
Cite this Quillbot article
We encourage the use of reliable sources in all types of writing. You can copy and paste the citation or click the "Cite this article" button to automatically add it to our free Citation Generator.
Merkus, J. (2025, November 26). Experimental Design | Types, Definition & Examples. Quillbot. Retrieved June 26, 2026, from https://quillbot.com/blog/research/experimental-design/
