Types of Validity in Research | Definition & Examples
Validity (more specifically, test validity) is whether a test or instrument is actually measuring the thing it’s supposed to. Validity is especially important in fields like psychology that involve the study of constructs (phenomena that cannot be directly measured).
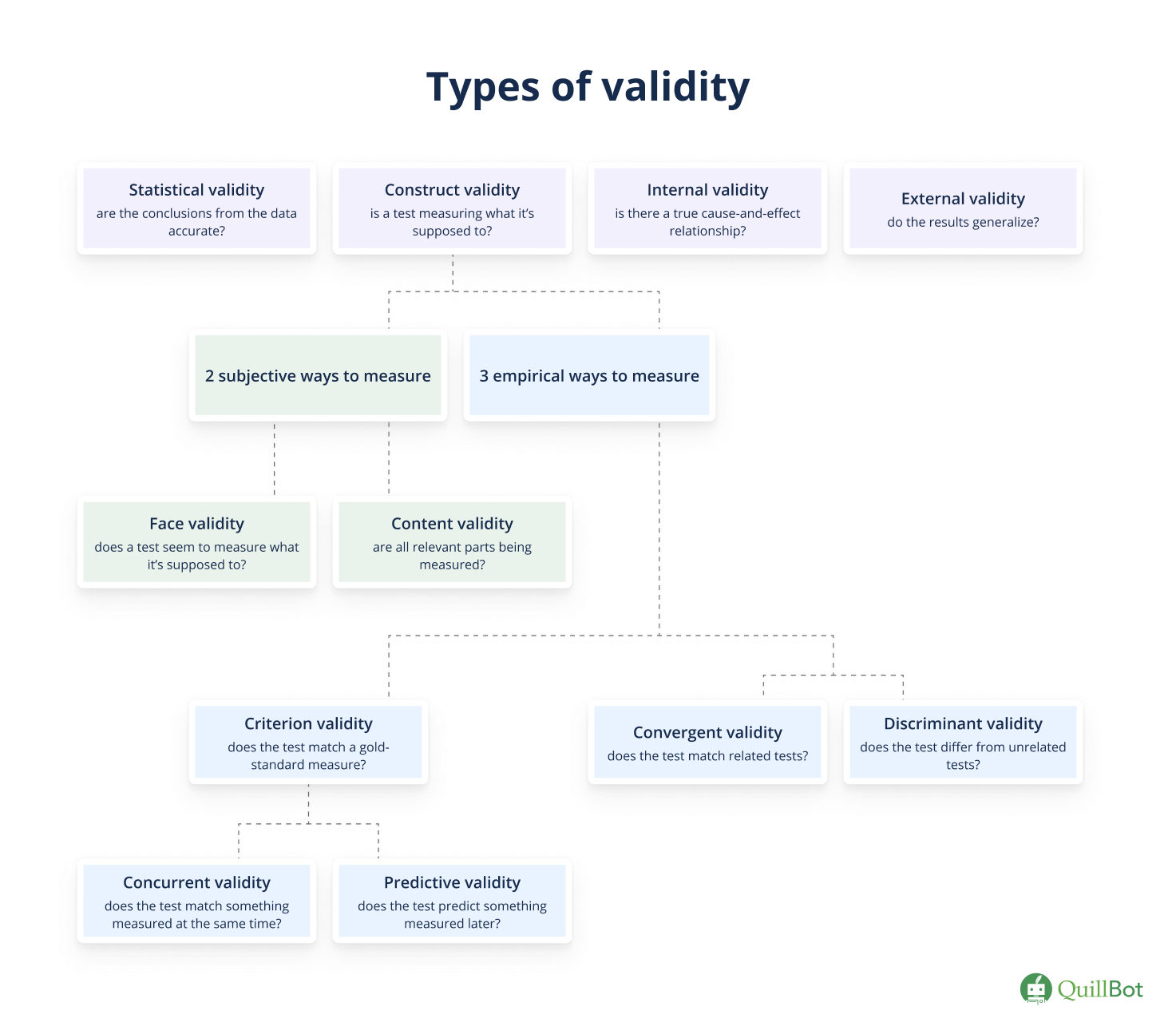
There are various types of test (or measurement) validity that provide evidence of the overall validity of a measure. Different types of validity in research include construct validity, face validity, content validity, criterion validity, convergent validity, and discriminant validity.
Test validity is the primary focus of this article. When conducting research, you might also want to consider experimental validity, which concerns research and experiment design more broadly. Internal validity, external validity, and ecological validity relate to the quality of a study and the applicability of its results to the real world.

What is validity?
When a researcher creates a new test or measure, they need to prove that it actually measures what it’s supposed to. The validity of a measure is whether it accurately captures the construct it’s been designed to measure. In this context, a construct is a phenomenon that cannot be directly measured.
Demonstrating the validity of a measure is no simple task. Decades of research have led scientists to define different types of validity that concern how well a test measures a construct. Current approaches treat these types of validity as evidence of the overall validity of a measure.
4 types of validity?
Many sources list four main types of validity: construct validity, content validity, face validity, and criterion validity. Within this framework, predictive and concurrent validity are subtypes of construct validity, and convergent and discriminant validity are forms of construct validity.
However, modern approaches instead consider construct validity the principal measure of validity. All other forms of validity provide evidence of construct validity. These types of validity can be separated into subjective measures (face and content validity) and empirical measures (criterion validity, convergent validity, and discriminant validity). Demonstrating the test validity of new measures or instruments is a nuanced and ever-evolving process.
Construct, face, content, criterion, convergent, and discriminant validity are forms of test validity; they assess whether a specific test measures the thing it should. Other types of experimental validity concern experiment design more broadly:
- Internal validity assesses whether an experimental manipulation actually leads to the observed effects (i.e., whether there is a true cause-and-effect relationship driving study results).
- External validity is whether the results from a study can be generalized to other situations, populations, settings, or measures.
- Ecological validity is how well an experiment design matches the natural environment. Experiments with high ecological validity are more likely to generalize to the real world. Ecological validity is often considered a subtype of external validity.
Construct validity
Construct validity concerns whether a measure captures the construct it’s supposed to. Construct validity is generally considered the overarching form of validity.
A construct is something that cannot be directly measured, like happiness or intelligence. Because we cannot directly measure constructs, we must instead operationalize them, or clearly define what observable variables we will use to represent them.
- Self-report measure: have someone rate their surprise on a scale from 1–5
- Physiological measure: record changes in a person’s pupil dilation, which has been linked to surprise
- Behavioral measure: observe changes in facial expression (raised eyebrows, open mouth)
How can we be sure that the measures in the previous example actually capture surprise? To provide evidence of the construct validity of their tests and measures, researchers evaluate different types of validity.
Face validity
Face validity is a qualitative assessment of validity. It concerns a key question: does this test seem to be measuring what it’s supposed to?
Face validity is a surface-level, subjective assessment of a test or measure. As such, it is considered a relatively weak form of validity.
Content validity
Another subjective type of validity is content validity. Content validity concerns whether a measure captures all relevant aspects of a construct. Content validity is generally evaluated by a subject-matter expert.
The teacher asks a colleague to assess the content validity of their test. Their colleague notes that the test only evaluates students’ knowledge of basic multiplication facts; no questions involve real-world problems. The test therefore lacks content validity.
Criterion validity
Criterion validity evaluates how well a measure corresponds to a well-established “gold-standard” measure, or criterion. It is important to assess criterion validity when creating a test that offers improvements over an existing measure.
Criterion validity is generally assessed by determining the correlation between the target measure and the criterion variable—a strong correlation provides evidence of criterion validity.
The two types of criterion validity are concurrent validity and predictive validity. They differ in the timing of target and criterion measurements.
- Concurrent validity assesses how well a target measure corresponds to a gold-standard measure taken at the same time, or concurrently.
- Predictive validity instead evaluates how well a target measure can predict a criterion measure taken in the future.
Concurrent validity: The company can determine the correlation between the survey results and the account’s current follower growth rate. A high correlation between the two would indicate high concurrent validity.
Predictive validity: To assess predictive validity, the company can administer the survey, then in six months compare its results to the number of new followers and sponsorship deals the account has gained. A high correlation would indicate that their survey is predictive of the future success of the account.
Concurrent and predictive validity both offer useful empirical evidence of the construct validity of a test. However, predictive validity is often considered more informative than concurrent validity as it captures how well a test can predict some real-world outcome.
A drawback of criterion validity is that it relies on the existence of a gold-standard criterion measure.
Convergent and discriminant validity
Convergent validity and discriminant validity provide empirical evidence of construct validity. Both involve comparing a target measure to tests of other constructs.
Convergent validity measures how well a target test matches tests of theoretically related constructs. If your test measures what you think it does, it should yield results that align with tests of similar phenomena (i.e., both measures should be strongly correlated).
Discriminant validity (less commonly referred to as divergent validity) assesses whether a target test produces results that differ from tests of unrelated constructs. A successful test should be able to measure the construct it’s been designed for without inadvertently measuring something else (i.e., the two measures should be uncorrelated or weakly correlated).
You can assess the convergent validity of your test by having a group complete both your survey and a test designed to measure sociability. Because extroversion and sociability are theoretically related, you expect the results to be strongly correlated.
Discriminant validity can be assessed by comparing teens’ scores on your survey to their scores on a test of neuroticism. Extroversion and neuroticism are distinct personality traits, so you expect to see a weak or non-existent correlation between these measures.
Reliability vs validity
Both reliability and validity must be considered for every measure. A reliable measure is one that yields the same results in the same circumstances.
Consider an oral thermometer used to take your temperature when you’re sick. If you use it three times in a row and it yields a very different result each time, it lacks reliability.
While reliability reflects consistency, validity concerns whether a measure actually captures what it’s supposed to. If the oral thermometer from the example above provides reliable results but is actually measuring the pH level of your saliva, it lacks validity.
A measure can be reliable but not valid (like a “thermometer” that provides consistent results but is actually measuring pH levels), but a measure that is unreliable cannot be valid (if a thermometer is providing different results when the temperature has not changed, it cannot be reflecting the true temperature).
Frequently asked questions about types of validity
- What is the difference between content and criterion validity?
-
Content validity and criterion validity are two types of validity in research:
- Content validity ensures that an instrument measures all elements of the construct it intends to measure.
- A survey to investigate depression has high content validity if its questions cover all relevant aspects of the construct “depression.”
- Criterion validity ensures that an instrument corresponds with other “gold standard” measures of the same construct.
- A shortened version of an established anxiety assessment instrument has high criterion validity if the outcomes of the new version are similar to those of the original version.
- Content validity ensures that an instrument measures all elements of the construct it intends to measure.
- Why are convergent and discriminant validity often evaluated together?
-
Convergent validity and discriminant validity (or divergent validity) are both forms of construct validity. They are both used to determine whether a test is measuring the thing it’s supposed to.
However, each form of validity tells you something slightly different about a test:
- Convergent validity indicates whether the results of a test correspond to other measures of a similar construct. In theory, there should be a high correlation between two tests that measure the same thing.
- Discriminant validity instead measures whether a test is similar to measures of a different construct. There should be a low correlation between two tests that measure different things.
If a test is measuring what it is supposed to, it should correspond to other tests that measure the same thing while differing from tests that measure other things. To assess these two qualities, you must determine both convergent and discriminant validity.
- What is the difference between concurrent validity and convergent validity?
-
Convergent validity and concurrent validity both indicate how well a test score and another variable compare to one another.
Convergent validity indicates how well one measure corresponds to other measures of the same or similar constructs. These measures do not have to be obtained at the same time.
Concurrent validity instead assesses how well a measure aligns with a benchmark or “gold-standard,” which can be a ground truth or another validated measure. Both measurements should be taken at the same time.
- How do you measure construct validity?
-
Construct validity assesses how well a test reflects the phenomenon it’s supposed to measure. Construct validity cannot be directly measured; instead, you must gather evidence in favor of it.
This evidence comes in the form of other types of validity, including face validity, content validity, criterion validity, convergent validity, and divergent validity. The stronger the evidence across these measures, the more confident you can be that you are measuring what you intended to.
- Why is validity so important in psychology research?
-
Psychology and other social sciences often involve the study of constructs—phenomena that cannot be directly measured—such as happiness or stress.
Because we cannot directly measure a construct, we must instead operationalize it, or define how we will approximate it using observable variables. These variables could include behaviors, survey responses, or physiological measures.
Validity is the extent to which a test or instrument actually captures the construct it’s been designed to measure. Researchers must demonstrate that their operationalization properly captures a construct by providing evidence of multiple types of validity, such as face validity, content validity, criterion validity, convergent validity, and discriminant validity.
When you find evidence of different types of validity for an instrument, you’re proving its construct validity—you can be fairly confident it’s measuring the thing it’s supposed to.
In short, validity helps researchers ensure that they’re measuring what they intended to, which is especially important when studying constructs that cannot be directly measured and instead must be operationally defined.
Cite this Quillbot article
We encourage the use of reliable sources in all types of writing. You can copy and paste the citation or click the "Cite this article" button to automatically add it to our free Citation Generator.
Heffernan, E. (2025, November 26). Types of Validity in Research | Definition & Examples. Quillbot. Retrieved June 29, 2026, from https://quillbot.com/blog/research/types-of-validity/
