Reliability vs Validity | Examples and Differences
When choosing how to measure something, you must ensure that your method is both reliable and valid. Reliability concerns how consistent a test is, and validity (or test validity) concerns its accuracy.
Reliability and validity are especially important in research areas like psychology that study constructs. A construct is a variable that cannot be directly measured, such as happiness or anxiety.
Researchers must carefully operationalize, or define how they will measure, constructs and design instruments to properly capture them. Ensuring the reliability and validity of these instruments is a necessary component of meaningful and reproducible research.
| Reliability | Validity | |
|---|---|---|
| Definition | Whether a test yields the same results when repeated. | How well a test actually measures what it’s supposed to. |
| Key question | Is this measurement consistent? | Is this measurement accurate? |
| Relationship | A test can be reliable but not valid; you might get consistent results but be measuring the wrong thing. | A valid test must be reliable; if you are measuring something accurately, your results should be consistent. |
| Example of failure | A bathroom scale produces a different result each time you step on it, even though your weight hasn’t changed. The scale is not reliable or valid. | A bathroom scale gives consistent readings (it’s reliable) but all measurements are off by 5 pounds (it’s not valid). |

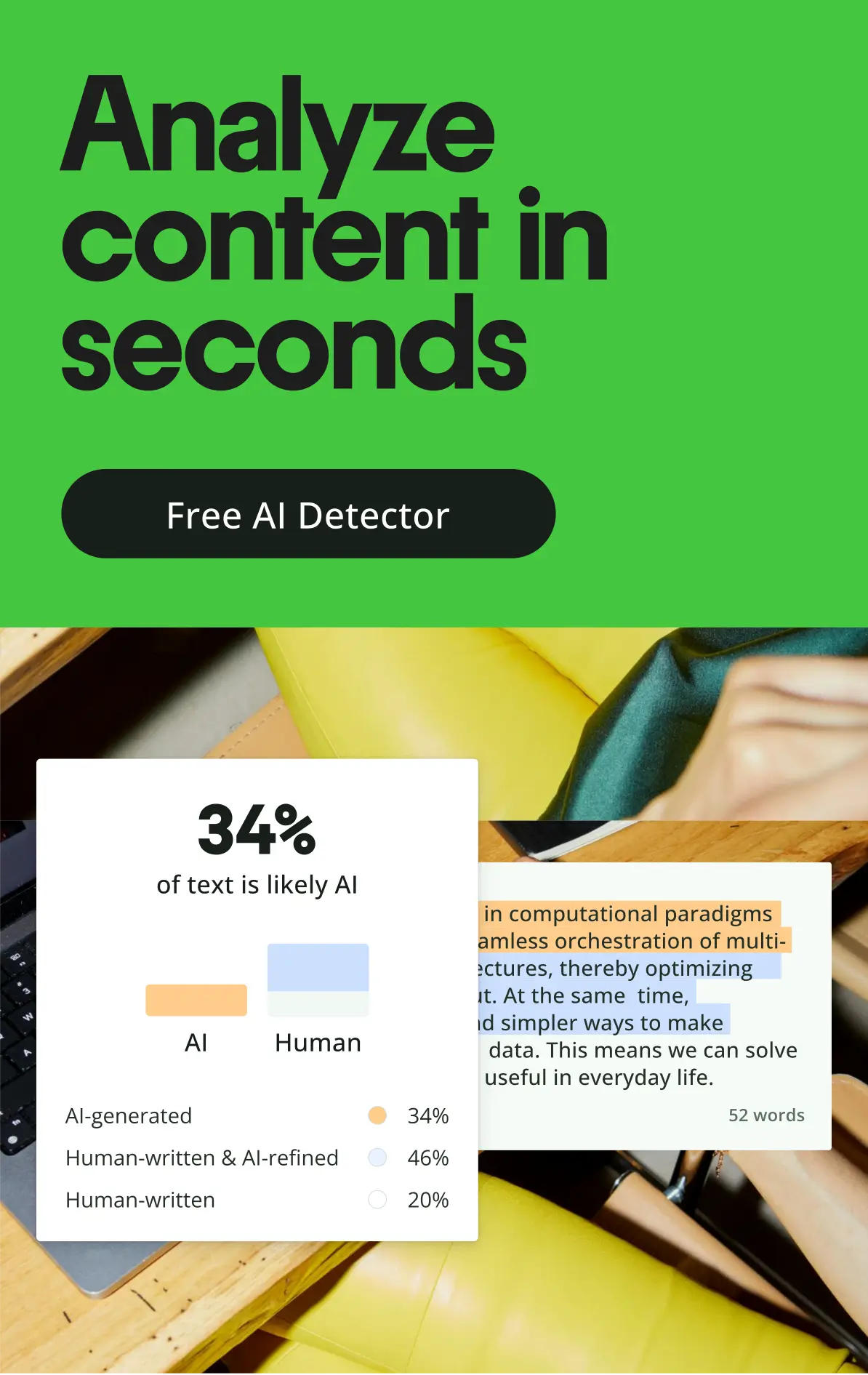
Understanding reliability and validity
Reliability and validity are closely related but distinct concepts.
What is reliability?
Reliability is how consistent a measure is. A test should provide the same results if it’s administered under the same circumstances using the same methods. Different types of reliability assess different ways in which a test should be consistent.
| Type of reliability | What it assesses | Example |
|---|---|---|
| Test-retest reliability | Does a test yield the same results each time it’s administered (i.e., is it consistent)? | Personality is considered a stable trait. A questionnaire that measures introversion should yield the same results if the same person repeats it several days or months apart. |
| Interrater reliability | Are test results consistent across different raters or observers? If two people administer the same test, will they get the same results? | Two teaching assistants grade assignments using a rubric. If they each give the same paper a very different score, the rubric lacks interrater reliability. |
| Internal consistency | Do parts of a test designed to measure the same thing produce the same results? | Seven questions on a math test are designed to test a student’s knowledge of fractions. If these questions all measure the same skill, students should perform similarly on them, supporting the test’s internal consistency. |
What is validity?
Validity (more specifically, test validity) concerns the accuracy of a test or measure—whether it actually measures the thing it’s supposed to. You provide evidence of a measure’s test validity by assessing different types of validity.
| Type of test validity | What it assesses | Example |
|---|---|---|
| Construct validity | Does a test actually measure the thing it’s supposed to? Construct validity is considered the overarching concern of test validity; other types of validity provide evidence of construct validity. | A researcher designs a game to test young children’s self-control. However, the game involves a joystick controller and is actually measuring motor coordination. It lacks construct validity. |
| Content validity | Does a test measure all aspects of the construct it’s been designed for? | A survey on insomnia probes whether the respondent has difficulty falling asleep but not whether they have trouble staying asleep. It thus lacks content validity. |
| Face validity | Does a test seem to measure what it’s supposed to? | A scale that measures test anxiety includes questions about how often students feel stressed when taking exams. It has face validity because it clearly evaluates test-related stress. |
| Criterion validity | Does a test match a “gold-standard” measure (a criterion) of the same thing? The criterion measure can be taken at the same time (concurrent validity) or in the future (predictive validity). | A questionnaire designed to measure academic success in freshmen is compared to their SAT scores (concurrent validity) and their GPA at the end of the academic year (predictive validity). A strong correlation with either of these measures indicates criterion validity. |
| Convergent validity | Does a test produce results that are close to other tests of related concepts? | A new measure of empathy correlates strongly with performance on a behavioral task where participants donate money to help others in need. The new test demonstrates convergent validity. |
| Discriminant validity | Does a test produce results that differ from other tests of unrelated concepts? | A test has been designed to measure spatial reasoning. However, its results strongly correlate with a measure of verbal comprehension skills, which should be unrelated. The test lacks discriminant validity. |
Test validity concerns the accuracy of a specific measure or test. When conducting experimental research, it is also important to consider experimental validity—whether a true cause-and-effect relationship exists between your dependent and independent variables (internal validity) and how well your results generalize to the real world (external validity).
In experimental research, you test a hypothesis by manipulating an independent variable and measuring changes in a dependent variable. Different forms of experimental validity concern how well-designed an experiment is. Mitigating threats to internal validity and threats to external validity can help yield results that are meaningful and reproducible.
| Type of experimental validity | What it measures | Example |
|---|---|---|
| Internal validity | Does a true cause-and-effect relationship exist between the independent and dependent variables? | A researcher evaluates a program to treat anxiety. They compare changes in anxiety for a treatment group that completes the program and a control group that does not. However, some people in the treatment group start taking anti-anxiety medication during the study. It is unclear whether the program or the medication caused decreases in anxiety. Internal validity is low. |
| External validity | Can findings be generalized to other populations, situations, and contexts? | A survey on smartphone use is administered to a large, randomly selected sample of people from various demographic backgrounds. The survey results have high external validity. |
| Ecological validity | Does the experiment design mimic real-world settings? This is often considered a subset of external validity. | A research team studies conflict by having couples come into a lab and discuss a scripted conflict scenario while an experimenter takes notes on a clipboard. This design does not mimic the conditions of conflict in relationships and lacks ecological validity. |
Reliability vs validity in research
Though reliability and validity are theoretically distinct, in practice both concepts are intertwined.
Reliability is a necessary condition of validity: a measure that is valid must also be reliable. An instrument that is properly measuring a construct of interest should yield consistent results.
However, a measure can be reliable but not valid. Consider a clock that’s set 5 minutes fast. If checked at noon every day, it will consistently read “12:05.” Though the clock yields reliable results, it is not valid: it does not accurately reflect reality.
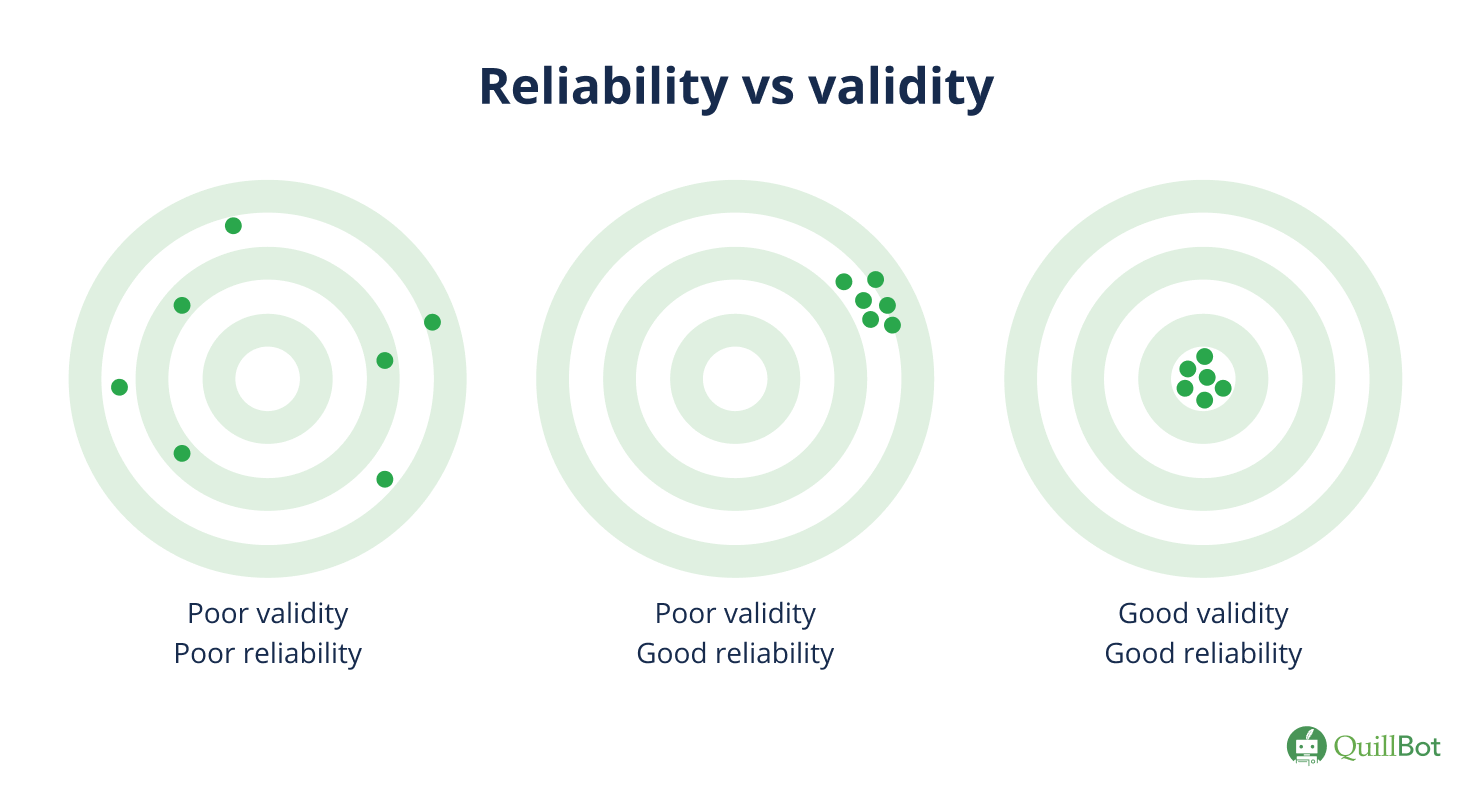
Because reliability is a necessary condition of validity, it makes sense to evaluate the reliability of a measure before assessing its validity. In research, validity is more important but harder to measure than reliability. It is relatively straightforward to assess whether a measurement yields consistent results across different contexts, but how can you be certain a measurement of a construct like “happiness” actually measures what you want it to?
Reliability and validity should be considered throughout the research process. Validity is especially important during study design, when you are determining how to measure relevant constructs. Reliability should be considered both when designing your study and when collecting data—careful planning and consistent execution are key.
Validity vs reliability examples
Reliability and validity are both important when conducting research. Consider the following examples of how a measure may or may not be reliable and valid.
- Reliability: This measure is not reliable—two observers might count smiles differently when observing the same meeting, leading to inconsistent results. The measure therefore lacks interrater reliability.
- Validity: Casey’s assumption that smiling signifies teamwork was incorrect. Her measure fails to capture aspects of teamwork like cooperation, communication, and collaboration. It lacks content validity, and its overall construct validity is poor.
Casey can choose a different measure in an attempt to improve the reliability and validity of her study.
- Reliability: This measure has high test-retest reliability. Provided someone has a consistent schedule, they will respond in the same manner each time they answer this question.
- Validity: Casey assesses the convergent validity of her new measure by determining the correlation between people’s responses and their teams’ performance metrics over the last quarter. There is no correlation between the two, which does not support the construct validity of this measure. The number of meetings a team has does not seem to capture how well they work as a team.
Even though the measure in the previous example is reliable, it lacks validity. Casey must try a different approach.
- Reliability: Casey ensures that her questionnaire includes clear, well-defined questions; has participants answer using well-structured Likert scales; and trains team members on how to respond objectively. This helps ensure the interrater reliability and test-retest reliability of her measure.
- Validity: Casey tests the test validity of her questionnaire using several approaches. She has an experienced manager evaluate whether her instrument addresses various aspects of teamwork to confirm content validity. She also once again compares her questionnaire results to team performance metrics and finds a high correlation between the two, indicating convergent validity. Casey also finds that questionnaire responses do not correlate with individual salaries, demonstrating divergent validity. This all provides evidence of the test validity of her questionnaire.
Frequently asked questions about reliability vs validity
- Why is validity so important in psychology research?
-
Psychology and other social sciences often involve the study of constructs—phenomena that cannot be directly measured—such as happiness or stress.
Because we cannot directly measure a construct, we must instead operationalize it, or define how we will approximate it using observable variables. These variables could include behaviors, survey responses, or physiological measures.
Validity is the extent to which a test or instrument actually captures the construct it’s been designed to measure. Researchers must demonstrate that their operationalization properly captures a construct by providing evidence of multiple types of validity, such as face validity, content validity, criterion validity, convergent validity, and discriminant validity.
When you find evidence of different types of validity for an instrument, you’re proving its construct validity—you can be fairly confident it’s measuring the thing it’s supposed to.
In short, validity helps researchers ensure that they’re measuring what they intended to, which is especially important when studying constructs that cannot be directly measured and instead must be operationally defined.
- What is a construct?
-
A construct is a phenomenon that cannot be directly measured, such as intelligence, anxiety, or happiness. Researchers must instead approximate constructs using related, measurable variables.
The process of defining how a construct will be measured is called operationalization. Constructs are common in psychology and other social sciences.
To evaluate how well a construct measures what it’s supposed to, researchers determine construct validity. Face validity, content validity, criterion validity, convergent validity, and discriminant validity all provide evidence of construct validity.
- What is the difference between test validity and experimental validity?
-
Test validity refers to whether a test or measure actually measures the thing it’s supposed to. Construct validity is considered the overarching concern of test validity; other types of validity provide evidence of construct validity and thus the overall test validity of a measure.
Experimental validity concerns whether a true cause-and-effect relationship exists in an experimental design (internal validity) and how well findings generalize to the real world (external validity and ecological validity).
Verifying that an experiment has both test and experimental validity is imperative to ensuring meaningful and generalizable results.
- What is an experiment?
-
An experiment is a study that attempts to establish a cause-and-effect relationship between an independent and dependent variable.
In experimental design, the researcher first forms a hypothesis. They then test this hypothesis by manipulating an independent variable while controlling for potential confounds that could influence results. Changes in the dependent variable are recorded, and data are analyzed to determine if the results support the hypothesis.
Nonexperimental research does not involve the manipulation of an independent variable. Nonexperimental studies therefore cannot establish a cause-and-effect relationship. Nonexperimental studies include correlational designs and observational research.
Cite this Quillbot article
We encourage the use of reliable sources in all types of writing. You can copy and paste the citation or click the "Cite this article" button to automatically add it to our free Citation Generator.
Heffernan, E. (2025, November 26). Reliability vs Validity | Examples and Differences. Quillbot. Retrieved July 5, 2026, from https://quillbot.com/blog/research/reliability-vs-validity/
